.svg)
.svg)
Overview
Traditionally, Python has been a blocking language when it comes to I/O and networking, meaning lines of code are executed one at a time. With network requests, we have to wait for the response before we can make another request. Meanwhile, our computers sit idling. Luckily, there are ways to address this, the most exciting of which is leveraging asynchronous requests with the aiohttp package. This article explains how asynchronicity can help solve these issues – and how you can put it into place within your own code!
Background: Python and Asynchronicity
Although Python is no stranger to asynchronicity with its multiprocessing package dating back to 2008, it didn't quite achieve the same status as the async/await paradigm in Javascript. With the release of Python 3.7, the async/await syntax has put our computers back to work and allowed for code to be performed concurrently. We can now fire off all our requests at once and grab the responses as they come in.
Multiprocessing enables a different level of asynchronicity than the async/await paradigm. Python’s multiprocessing package enables multi-core processing. This means the same code can run concurrently on separate processes without blocking one another. This allows for true parallelism of CPU-bound tasks. It can be overkill if you require concurrency on tasks that are simply I/O bound which the async/await paradigm is better suited for.
Asynchronous Pinwheels
At Pinwheel, we have an API for retrieving payroll data such as Paystubs, Income, Identity, Shifts, Employment, and Direct Deposit Allocations data. It takes no stretch of the imagination that getting this info can involve a lot of requests.
Pinwheel uses async/await to concurrently retrieve payroll data. Implementing a project with asynchronous requests can yield enormous benefits by reducing latency. Using asynchronous requests has reduced the time it takes to retrieve a user's payroll info by up to 4x. To see async requests in action we can write some code to make a few requests. Read on to learn how to leverage asynchronous requests to speed-up python code.
Trying out async/await
Let's write some code that makes parallel requests. To test this we can use the Coinbase API to get the current prices of various cryptocurrencies.
Coroutine Maintenance
The aiohttp package is emerging as the standard for handling asynchronous HTTP requests. To get started we can install the aiohttp package.
$ pip install aiohttp
view rawinstall.sh hosted with ❤ by GitHub
We can leverage aiohttp and the builtin aysncio package to make requests. Our first function that makes a simple GET request will create in async land what is called a coroutine. Coroutines are created when we combine the async and await syntax.
async def get_url(session: aiohttp.ClientSession, url: str) -> Dict: async with session.get(url) as response: return await response.json()
view rawget_url.py hosted with ❤ by GitHub
In the above example (modeled off of the aiohttp request lifecycle example from the docs) we take in aiohttp's ClientSession and a URL as arguments and call .get() on the ClientSession. One of the big differences between aiohttp and the old school requests package is that the response attributes live inside a context manager (under the hood the dunder methods __aenter__ and __aexit__ are being called). That means if we want to do something with status codes or response history we need to do so within this block.
...async with session.get(url) as response: if response.status == 503: # do some work
view rawstatus_code.py hosted with ❤ by GitHub
If we are making a request to an endpoint that returns JSON content we would naturally like to turn the response into a python dictionary. In the function above we use .json() to do just that. We could also await .text() to turn HTML into a string or even .read() to handle byte content (ie. pdfs maybe?).
What about POST? Swap out .get() for .post() and then pass whatever payload you need in the data kwarg.
async with session.post(url, data=payload) as response: ...
view rawpost.py hosted with ❤ by GitHub
A List of Tasks
The next step is to set up session persistence that we can maintain in all our requests. Luckily aiohttp's ClientSession allows us to do this. The following code block creates the Client Session to pass into the get_url function.
async def request_urls(urls: List[str]): async with aiohttp.ClientSession() as session: tasks: List[asyncio.Task] = [] for url in urls: tasks.append( asyncio.ensure_future( get_url(session, url) ) ) return await asyncio.gather(*tasks)
view rawtasks.py hosted with ❤ by GitHub
We are again using a context manager but this time to handle the session. The great thing about reusing the ClientSession like this is that any headers or cookies passed to the session will be used for all of our requests. When we instantiate the ClientSession this is where we can pass headers, cookies, or a TraceConfig object (for logging!) as kwargs.
async with aiohttp.ClientSession( headers=headers_dict, cookies=cookies_dict, trace_configs=[trace_config],) as session: ...
view rawheaders_cookies.py hosted with ❤ by GitHub
Back to the Future
Next we are creating a list of tasks to execute. Asyncio's method ensure_future allows for coroutines to be turned into Tasks so they are not immediately called. In our case we want the coroutine get_url that we wrote above to be converted into a Task.
task: asyncio.Task = asyncio.ensure_future( get_url(session, url))
view rawfuture.py hosted with ❤ by GitHub
The tasks are then passed to asyncio's gather which schedules each coroutine.
async def request_urls(urls: List[str]): tasks: List[asyncio.Task] = [] ... return await asyncio.gather(*tasks)
view rawgather.py hosted with ❤ by GitHub
The final step is to pass the request_urls function to Asyncio's run method. Remember that request_urls is in fact just a coroutine defined by the async/await syntax. This asyncio method will execute our coroutine and concurrently execute the scheduled tasks.
responses: List[Dict] = asyncio.run(request_urls(urls))
view rawresponses.py hosted with ❤ by GitHub
All Together Now
Let's see it all together! Here is some code that makes concurrent requests to the Coinbase API to get crypto to USD exchange rates.
import asyncioimport aiohttpCRYPTOS: List[str] = [ "BTC", "ETH", "DOGE", "BCH", "ETC", "LTC",]URLS: List[str] = [ f"https://api.coinbase.com/v2/prices/{crypto}-USD/buy" for crypto in CRYPTOS]async def request_urls(urls: List[str]): async with aiohttp.ClientSession() as session: tasks: List[asyncio.Task] = [] for url in urls: tasks.append( asyncio.ensure_future( get_url(session, url) ) ) return await asyncio.gather(*tasks)async def get_url(session: aiohttp.ClientSession, url: str) -> Dict: async with session.get(url) as response: return await response.json()responses: List[Dict] = asyncio.run(request_urls(URLS))print(responses)
view rawasync_crypto.py hosted with ❤ by GitHub
Running the code, we get the list of dicts printed to the console. The best part is that the responses are in the same order as our urls. Even if the last endpoint comes in first aiohttp doesn't reorder our list.
$ python3 async_crypto.py[{'data': {'base': 'BTC', 'currency': 'USD', 'amount': '58995.78'}}, {'data': {'base': 'ETH', 'currency': 'USD', 'amount': '4467.16'}}, {'data': {'base': 'DOGE', 'currency': 'USD', 'amount': '0.22'}}, {'data': {'base': 'BCH', 'currency': 'USD', 'amount': '582.49'}}, {'data': {'base': 'ETC', 'currency': 'USD', 'amount': '48.59'}}, {'data': {'base': 'LTC', 'currency': 'USD', 'amount': '208.84'}}]
view rawgistfile1.sh hosted with ❤ by GitHub
So what kind of benefits can we see? To see the difference in latency let's do an A/B test, comparing sync requests using pythons requests package vs async requests with aiohttp. To do this we can use the time package to measure the difference in seconds for the requests approach below and the async request_urls function.
from time import timeresponses: List[Dict] = []start_time: float = time()for url in URLS: responses.append(requests.get(url).json())end_time: float = time()print(end_time - start_time)
view rawtime_test.py hosted with ❤ by GitHub
Looking at the average time it takes to request endpoints sync vs. async, even with the small list of six URLs, we can see a clear winner. One can only imagine the benefits when a list of URLs is much larger!
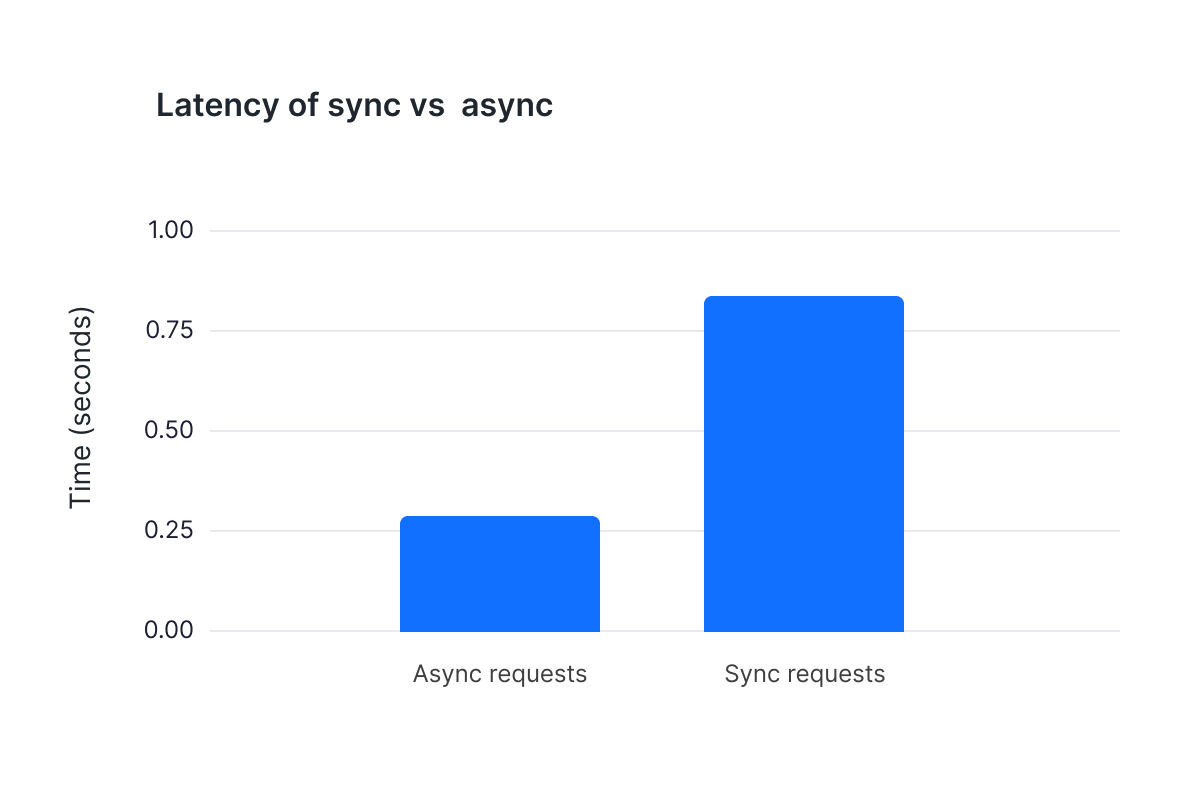
And that's it! Asynchronous requests using aiohttp is a great tool for speeding up your code. There are many other options for executing code concurrently and plenty of use cases for making requests one at a time. But concurrent code is becoming a bigger part of Python and understanding asynchronicity is a powerful asset.